Machine learning projects nearly always entail the understanding and classifying data and one of the more difficult steps in the machine learning process is to choose the best classification model. Classification models are used to assign data to a discrete group or class based on a specific set of features. Many practitioners will run several different classification models to find the best model for the given data. We will try and provide a better understanding of some of the more common classification models to help you with your machine learning project.
There are two very simplistic methods to decide the best classification model to use for machine learning. The first is if your problem is linear, you should use a logistic regression or support vector machine. To understand if the problem is linear, when plotted on a graph the data traces a straight line and changes in an independent variable always produces a corresponding change in the dependent variable. If your problem is non-linear, you should look to K-Nearest Neighbor, Naive Bayes, Decision Tree or Random Forest.
Let’s look at some of the more popular classification models
Support Vector Machine
The support vector machine (SVM) works best when your data has exactly two classes. The SVM classifies data by finding the best hyperplane that separates all data points of one class from those of the other class. The real advantages of SVM comes from its accuracy and the fact that it tends not to overfit the data. 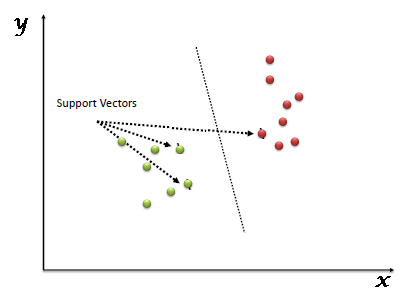 SVM is also a fast option because the model is just deciding between two classes of data. SVMs require an investment in time in the beginning to train the model before it can be used. Once you start using SVM with more than two classes of data, the speed of the SVM will be impacted.
SVM is also a fast option because the model is just deciding between two classes of data. SVMs require an investment in time in the beginning to train the model before it can be used. Once you start using SVM with more than two classes of data, the speed of the SVM will be impacted.
k-Nearest Neighbor
k-Nearest Neighbor (kNN) works with data, where the introduction of new data is to be assigned to a category. The kNN model looks for the specified k number of nearest neighbors, so if k is 10, then you find the class of 10 nearest neighbors (or similar data). The model effectively looks to see where the data should be classed. It works by choosing the number “k” of neighbors. The kNN is identified with the introduction of a new data point. 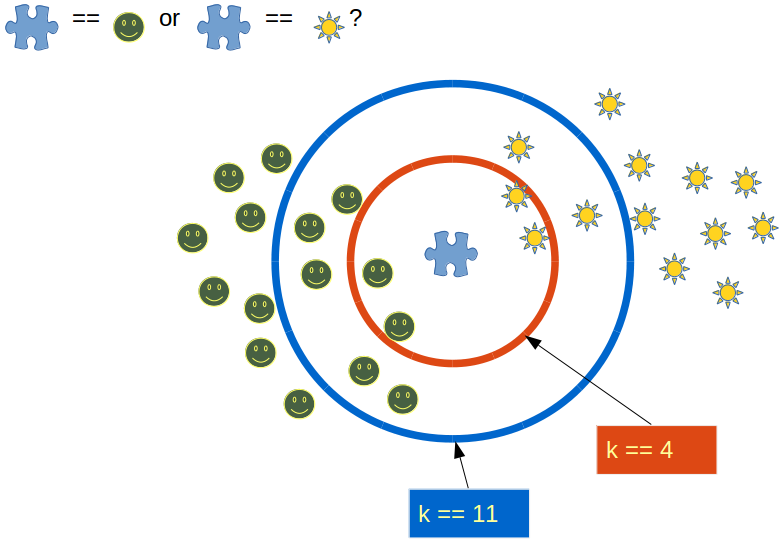 This is achieved by calculating the Euclidean distance, the formula of which is Square Root (X2 – X1)2 + (y2 – y1)2. Among these K neighbors, you count the number of data points in each category and assign the new data point to the category where you counted the most number of neighbors.
This is achieved by calculating the Euclidean distance, the formula of which is Square Root (X2 – X1)2 + (y2 – y1)2. Among these K neighbors, you count the number of data points in each category and assign the new data point to the category where you counted the most number of neighbors.
Naïve Bayes
Naïve Bayes is a great model if the data is not complex and your task is relatively simple. The Naïve component relies on independence assumptions and looks for the likelihood point from a data set that will exhibit similar features to a new random variable. It is a high bias/low variance classifier and is helpful when working with a limited amount of data. Due to the simple nature of Naïve Bayes, it does not tend to overfit data, enabling the ability to train data quickly.

Decision Trees
To see how a decision tree predicts a response, the user will follow the decisions in that tree from the beginning node down to a leaf node (each split in the tree is called a leaf) which contains the response. Classification trees give responses that are nominal, such as true or false. Decision trees are relatively easy to follow and you can see a full representation of the path taken from the beginning (root) to the leaf. This is great is you need to share the results as it provides evidence of how a conclusion is reached. The derivation of a Decision Tree is Random Forest Regression, which is where the same algorithm is applied multiple times – effectively a team of decision trees offering an average of different predictions.
So which classifier should you use?
From a business point of view, you would rather use Logistic Regression or Naive Bayes when you want to rank your predictions by their probability. For example, if you want to rank your customers from the highest probability that they buy a certain product, to the lowest probability. Eventually that allows you to target your marketing campaigns. And of course, for this type of business problem, you should use Logistic Regression if your problem is linear, and Naive Bayes if your problem is non-linear.
SVM classification works when you want to predict to which segment your customers belong to. Segments can be any kind of segments, for example some market segments you had identified earlier when clustering customers. A decision Tree is great when you want to have a clear interpretation of your model results, and Random Forest when you are just looking for high performance with less need for interpretation.
Black Belt Digital can support your business to articulate how Machine Learning can deliver business solutions. We offer practical solutions, with proven experience, in machine learning and artificial intelligence.
References:
Matlab; Machine Learning Challenges: Choosing the Best Model and Avoiding Overfitting
http://www.businessdictionary.com/definition/linear-relationship.html